
Computer vision has transformed industries like healthcare, security, retail, and autonomous systems. However, pre-trained AI models from OpenAI, Google, or Meta are designed for general tasks and often struggle with domain-specific applications. Since these models are trained on broad datasets, they may lack the precision needed for specialized real-world scenarios, resulting in lower accuracy and higher error rates.
For example, a general object detection model may recognize different types of vehicles but struggle to differentiate between an emergency vehicle and a regular car in real-time traffic monitoring. Similarly, pre-trained models may not detect rare medical conditions in radiology scans due to a lack of domain-specific training data. This is where custom-trained computer vision models become necessary—they allow for fine-tuned accuracy, adaptability to unique environments, and compliance with industry-specific regulations.
This article explores why custom-trained computer vision models are essential, the prerequisites for training them, and the crucial role of data annotation in ensuring high-performance AI solutions.
Why Do We Need a Custom-Trained Computer Vision Model?
Pre-trained models, such as those offered by OpenAI, Google, or Meta, perform well on general tasks like object detection and classification. However, for industry-specific applications—such as detecting defective products in manufacturing, recognizing medical anomalies in X-rays, or identifying safety risks in industrial environments—pre-trained models often fall short.
A custom-trained model ensures:
- Higher accuracy for specific tasks by learning from domain-specific data.
- Adaptability to unique environments where lighting, angles, or conditions differ from generic datasets.
- Reduced false positives and false negatives, which is critical in safety and healthcare applications.
- Better compliance with privacy regulations, as you can train the model on proprietary or anonymized datasets.
Prerequisites for Training a Custom Vision Model
Before training a computer vision model, certain prerequisites must be met:
- Well-Defined Objective: Clearly outline what the model is supposed to detect, classify, or segment.
- High-Quality Dataset: Gather relevant images or video frames covering different scenarios, variations, and edge cases.
- Data Annotation Strategy: Decide on annotation types (bounding boxes, segmentation masks, key points, etc.) and quality control measures.
- Handling Multiple Classes: If the dataset consists of multiple object classes, ensure proper labeling format and class separation in the annotation files.
- Hardware & Computational Resources: Leverage GPUs, cloud platforms, or edge devices for efficient training and deployment.
- Algorithm Selection: Choose a suitable neural network architecture (e.g., YOLO, Mask R-CNN, or Vision Transformers) based on the task.
- Evaluation Metrics: Define accuracy, precision, recall, and other KPIs to measure model performance.
The Role of Data Annotation and Why It Matters
Machine learning models are only as good as the data they learn from. In computer vision, annotated data provides the ground truth necessary for supervised learning. Without proper annotation, even the most advanced AI model would struggle to make accurate predictions.
Why Do We Need Annotated Data?
- Supervised Learning: AI models rely on labeled data to learn patterns and features.
- Performance Improvement: High-quality annotations ensure higher accuracy in object detection and classification.
- Bias Reduction: Diverse and well-annotated datasets help in minimizing model bias.
- Model Generalization: Ensures the model performs well across different environments and lighting conditions.
Best Practices for Data Annotation
Data labeling is a meticulous process that requires consistency and precision. Here are key aspects to consider while annotating data:
1. Best Practices for Data Annotation
- Clearly define the labeling standards to maintain consistency across annotators.
- Provide examples of correct and incorrect annotations.
2. Annotation Types
- Bounding Boxes: Used for object detection.
- Polygons/Segmentation Masks: Required for detailed object boundaries.
- Keypoints: For pose estimation (e.g., tracking human joints).
- Instance Segmentation: Distinguishing between multiple objects of the same class.
3. Handling Multiple Classes in Data Annotation
When working with multiple object classes, it’s essential to structure the dataset properly. Most deep learning frameworks require a structured YAML file to define class mappings and dataset paths. Here’s an example of a typical YAML configuration for YOLO-based models:
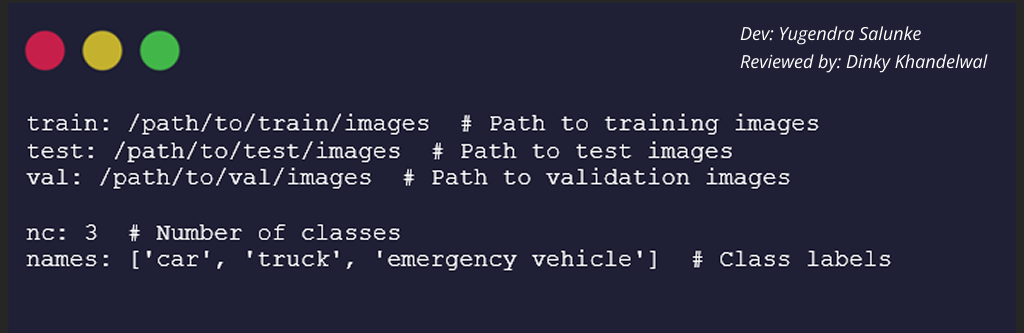
Each annotated image should have a corresponding .txt file with label information structured as

For example, a drowning class object detected in an image might be labeled as:

This means:
- Class 2 (emergency vehicle)
- Bounding box center at (0.45, 0.56) in normalized coordinates
- Width 0.32, Height 0.40
4. Quality Control
- Implement multi-level validation by multiple annotators.
- Use automation-assisted labeling to speed up the process.
- Perform regular audits on annotated data to detect inconsistencies.
5. Diversity in Dataset
- Ensure that images are captured under different lighting conditions, angles, and backgrounds.
- Include edge cases and challenging scenarios to improve robustness.
5. Annotation Tools and Platforms
Several tools and platforms facilitate data annotation, each catering to different needs. Here are some of the widely used ones:
- Labelbox – A comprehensive platform with AI-assisted labeling and workforce management.
- SuperAnnotate – Ideal for scalable annotation projects with collaboration features.
- VIA (VGG Image Annotator) – Open-source and lightweight for quick manual labeling.
- Roboflow – Offers preprocessing tools and annotation management.
- CVAT (Computer Vision Annotation Tool) – Developed by Intel, supports complex labeling tasks.
- Amazon SageMaker Ground Truth – Provides managed annotation services with automation.
- Scale AI – Used by enterprises for high-quality data annotation with human-in-the-loop refinement.
Conclusion
Training a custom computer vision model requires a well-structured dataset, careful annotation, and a strategic approach to machine learning. Data annotation is a crucial step that directly impacts model accuracy, and investing in quality annotation tools and best practices is essential for achieving high-performance AI models.
When handling multiple classes, ensuring the dataset structure is well-defined is critical for proper training. Using a structured YAML file, labeling each object accurately, and verifying annotations through quality control measures will significantly enhance model performance.
As AI-driven applications continue to grow, ensuring high-quality labeled datasets will remain a key factor in pushing the boundaries of computer vision capabilities. Organizations looking to deploy robust AI solutions should prioritize an efficient and precise annotation process for better model performance and reliability.