
Understanding the Evolution of Automation
If you’ve landed on this blog, chances are you’ve either read our previous post on data annotation or you’re looking for the most efficient way to train a custom object detection model. Either way, you’re in the right place.
Object detection has seen significant advancements, and multiple models perform well for this task. Some popular ones include:
- Faster R-CNN: A two-stage detector that provides high accuracy but is slower compared to single-stage models.
- SSD (Single Shot MultiBox Detector): A faster alternative to R-CNNs, ideal for real-time applications but slightly less accurate.
- RetinaNet: Balances accuracy and speed with a focus on handling class imbalance using focal loss.
- EfficientDet: Uses compound scaling and lightweight architecture to achieve high performance with fewer parameters.
However, in this blog, we focus on YOLO (You Only Look Once) because it is fast, easy to use, and offers a great balance between accuracy and inference speed.
Why YOLO?
YOLO is one of the most efficient object detection models due to the following characteristics:
- Real-Time Performance: YOLO processes images in a single pass, making it ideal for real-time applications.
- End-to-End Detection: Unlike region-based models (e.g., Faster R-CNN), YOLO detects objects directly from an image, leading to faster inference.
- Scalability: With multiple versions and model sizes, YOLO can be deployed on edge devices and high-performance GPUs alike.
- Ease of Use: Well-documented frameworks like Ultralytics' YOLOv8 make training and deployment simple.
1. Choosing the Right YOLO Model Variant
Before jumping into training, it is important to determine which YOLO variant best suits your needs. Different versions of YOLO offer trade-offs between speed and accuracy:
- YOLOv8n (Nano): Best for edge devices with limited computational power.
- YOLOv8s/m: Balanced between speed and accuracy for mid-range applications.
- YOLOv8l/x: Suitable for high-accuracy tasks but requires more computational resources.
- YOLOv5/YOLOv7: Useful if you need specific architecture optimizations or legacy support.
For more on preparing your data environments for AI, refer to our blog on AI Readiness.
2. Optimizing Your Dataset for YOLO Training
Your dataset quality directly impacts model performance. Here’s how to set it up efficiently:
- Ensure High-Quality Annotations: Use tools like Roboflow, LabelImg, or CVAT for precise bounding boxes.
- Diversity and Balance: Include diverse scenarios and a balanced class distribution.
- Proper Image Size Selection: YOLO performs well with squared image sizes (e.g., 640x640 or 960x960) to balance resolution and speed.
- Augmentation Techniques: Use techniques like:
- Horizontal and vertical flips
- Rotations and translations
- Random brightness, contrast, and saturation adjustments
- Gaussian noise and blur
- Random cropping and scaling
These are some major augmentations increase variability in training data and help improve model generalization.
3. Hyperparameter Tuning: Finding the Sweet Spot
Tuning the right hyperparameters is key to getting the best results. Here are a few essential ones:
- Learning Rate: A lower learning rate (e.g., 0.001) is usually a good start, but consider learning rate schedulers (e.g., cosine, step) for better convergence.
- Batch Size: A larger batch size stabilizes training, but ensure your GPU can handle it.
- Epochs: Typically, 50-100 epochs are sufficient—monitor validation loss to prevent overfitting.
- Optimizer: Adam offers faster convergence, while SGD helps with better generalization in larger datasets.
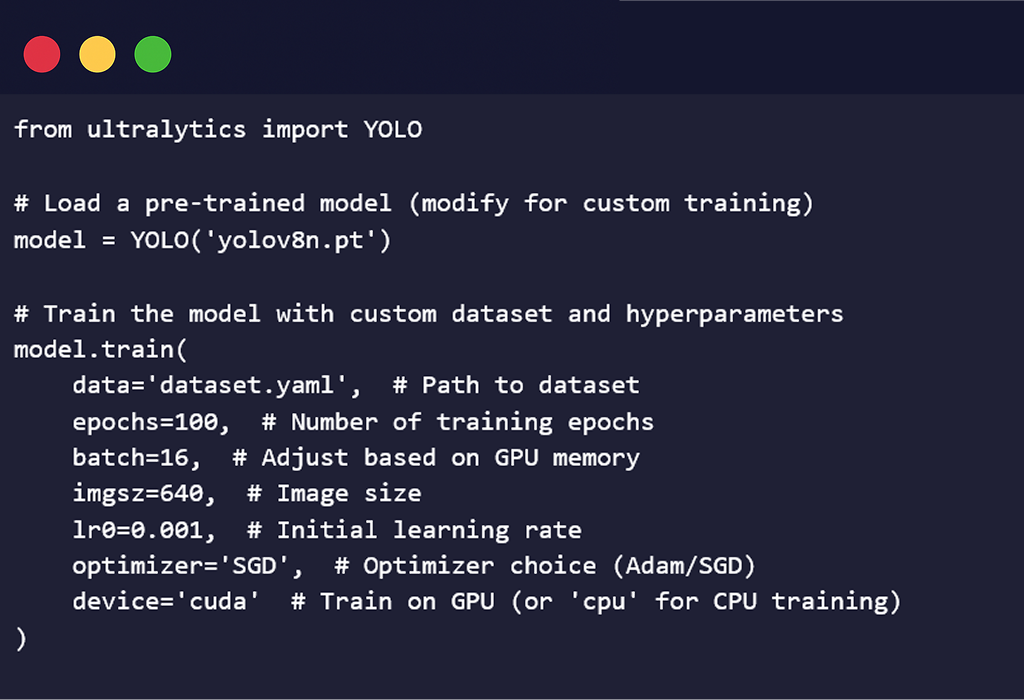
Example Training Script with some major Hyper Parameters:
4. Training Environment and Hardware Considerations
Training a YOLO model efficiently also depends on your hardware setup. Here are some key factors:
On-Premise Training
- Local GPU Machines: Ideal for full control and customization. Recommended for smaller teams or limited budget.
- Edge Devices (Jetson Nano, Raspberry Pi): Suitable for lightweight models like YOLOv8n, but limited in compute power.
Cloud-Based Training
- AWS (EC2, SageMaker): Scalable infrastructure with on-demand GPU instances.
- Google Cloud Platform (Vertex AI, Colab Pro): Easy integration with Jupyter notebooks and TPU support.
- Azure ML: Enterprise-grade ML lifecycle management with GPU/TPU options.
Tips for Better Efficiency
- Use GPU Acceleration: Training on an NVIDIA GPU with CUDA is significantly faster than CPU.
- Mixed Precision Training: Reduces memory consumption while maintaining performance.
- Distributed Training: For large-scale datasets, consider multi-GPU or TPU training.
5. Avoiding Common Pitfalls in YOLO Training
To ensure optimal results, avoid these common mistakes:
- Insufficient Data Preprocessing: Poor-quality annotations, missing labels, or incorrect formats degrade performance.
- Overfitting to Training Data: Monitor validation loss and apply regularization techniques like dropout or weight decay.
- Ignoring Class Imbalance: If some classes dominate, use class weighting or focal loss to balance learning.
- Inconsistent Image Sizes: Ensure all images are resized properly before feeding into the model.
- Not Testing on Real Data: Always validate performance on unseen test data before deployment.
Conclusion
While several object detection models exist, YOLO remains a top choice due to its speed, efficiency, and ease of deployment. Training a YOLO model efficiently requires a strategic approach—from selecting the right variant, setting up a high-quality dataset, tuning hyperparameters, and choosing the right infrastructure. By following these best practices, you can build an accurate and robust object detection model tailored to your specific needs.